|
|
| (5 revisiones intermedias por el mismo usuario no mostrado) |
| Línea 4: |
Línea 4: |
| | = Screen Scraping :: Aumentando el poder de la web= | | = Screen Scraping :: Aumentando el poder de la web= |
| | | | |
| − | Luis Miguel Morillas <lmorillas at xml3k.org> | + | Luis Miguel Morillas <lmorillas at xml3k.org> |
| | + | |
| | + | Zaragoza, 10 de noviembre de 2011 |
| | | | |
| | identi.ca: lmorillas | | identi.ca: lmorillas |
| Línea 15: |
Línea 17: |
| | | | |
| | ===¿POR QUÉ HACER SCRAPING?=== | | ===¿POR QUÉ HACER SCRAPING?=== |
| | + | * Web de datos |
| | + | |
| | * En la web hay mucha información | | * En la web hay mucha información |
| | * No siempre estructurada (opendata) | | * No siempre estructurada (opendata) |
| − | * Web de datos
| |
| | * '''Divertido''' | | * '''Divertido''' |
| | + | </div> |
| | + | |
| | + | <div class="slide nobackground"> |
| | + | ===¿DÓNDE/CÓMO ESTÁN LOS DATOS?=== |
| | + | ''¿A qué hora es la charla de Jython?'' |
| | + | [[Archivo:Lswc horario codigo.png]] |
| | + | |
| | </div> | | </div> |
| | | | |
Última revisión de 08:31 10 nov 2011
Screen Scraping :: Aumentando el poder de la web
Luis Miguel Morillas <lmorillas at xml3k.org>
Zaragoza, 10 de noviembre de 2011
identi.ca: lmorillas
1. Intro
¿POR QUÉ HACER SCRAPING?
- En la web hay mucha información
- No siempre estructurada (opendata)
- Divertido
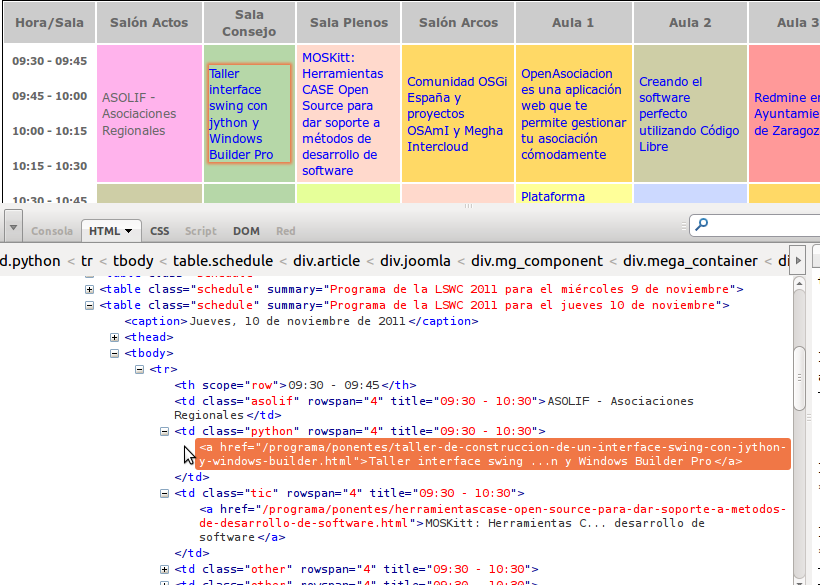
¿DÓNDE/CÓMO ESTÁN LOS DATOS?
¿A qué hora es la charla de Jython?
CONDICIONES LEGALES
Robots y Screen Scraping (raspado de pantalla): Usted no podrá usar
minería de datos ("data mining"), robots, screen scraping o herramientas
similares de acumulación y extracción de datos en este sitio de red,
salvo con nuestro consentimiento expreso y por escrito tal y
como se indica a continuación.
http://www.imdb.es/help/show_article?conditions
¿POR QUÉ PYTHON?
- Muy fácil para "no programadores"
- Muchos módulos, herramientas, ejemplos y documentación.
- Desarrollo muy rápido y eficiente
- Open-source
2. ¿Cómo?
PROCESO GENERAL
- Analizar
- Buscar patrones
- Extracción de datos
¿BÚSQUEDA EN EL TEXTO BRUTO?
import urllib2
URL = 'http://www.libresoftwareworldconference.com/'
source = urllib2.urlopen(URL).read()
- Proceso del texto (Búsqueda subcadenas ...)
- Expresiones regulares
NO. MEJOR USAMOS LIBRERÍAS ...
- Beautiful Soup
- lxml
- html5lib
- mechanize
- scrapemark
- pyquery
- scrapy
...
MÁS DETALLES
- Implementada en C y Pyhton
- Parser basado en Expat
- API para recorrido de nodos muy eficiente y sencilla
- Python, XPath, InfoSet
- XPath (& binding dinámico de objetos)
- XSLT (& enlazado con funciones en Python)
- Aserciones basadas en Schematron (validación de modelos)
- Licencia tipo Apache
CREANDO DATOS PARA LA WEB: AKARA
- Akara es un framework para construir apps RESTful basadas en datos
- Aplicando sencillos wrappers (decoradores) transformamos funciones en serviciios REST
- Funciona como un repositorio de servicios con autodiscover
3. Práctica
Scraping the web with amara


